
Learning outcomes
The learning outcomes of this chapter are:
- Apply actor-critic methods to solve small-scale MDP problems manually and program actor critic algorithms to solve medium-scale MDP problems automatically.
- Compare and contrast actor-critic methods with policy gradient methods like REINFORCE and value-based reinforcement learning.
The sample efficiency problem in REINFORCE leads to issues with policy convergence. As with Monte-Carlo simulation, the high variance in the cumulative rewards [latex]G[/latex] over episodes leads to instability.
Actor critic methods aim to mitigate this problem. The idea is that instead of learning a value function or a policy, we learn both. The policy is called the actor and the value function is called the critic. The primary idea is that the actor produces actions, and as in temporal difference learning, the value function (the critic) provides feedback or “criticism” about these actions as a way of bootstrapping.
Q Actor-Critic
The Q Actor Critic algorithm uses a Q-function as the critic.
Algorithm 14 (Q Actor Critic)
Note that we have two different learning rates [latex]\alpha_w[/latex] and [latex]\alpha_{\theta}[/latex] for the Q-function and policy respectively.
Let’s analyse the key parts in more detail. The line that updates [latex]\delta[/latex] is the same as the [latex]\delta[/latex] calculation in SARSA: it is temporal difference value for executing action [latex]a[/latex] in state [latex]s[/latex], with the estimate of the future discount reward being [latex]Q_w(s',a')[/latex].
Once the [latex]\delta[/latex] value is calculated, we update both the actor and the critic. The weights of the critic [latex]Q_w[/latex] are updated by following the gradient [latex]\nabla Q_w(s,a)[/latex] of the critic Q-function at [latex]s,a[/latex], and then the parameters of the actor [latex]\theta[/latex] are updated the same way as in REINFORCE, except that the value of [latex]\delta[/latex] uses the temporal difference estimate based on [latex]Q_w(s,a)[/latex] instead of using [latex]G[/latex].
So, this simulataneously learns the policy (actor) [latex]\pi_{\theta}[/latex] and a critic (Q-function) [latex]Q_w[/latex], but the critic is learnt only to provide the temporal difference update, not to extract the policy.
But wait! Didn’t we say early that the weakness of value-based methods was that they could not extend to continuous action spaces? Haven’t we now gone backwards by including a Q-function? Why not just use the Q-function directly?
The reason the actor critic methods still work like this is because the actor policy [latex]\pi_{\theta}[/latex] selects actions for us, while the critic [latex]Q_w(s,a)[/latex] is only ever used to calculate the temporal difference estimate for an already selected action. We do not have to iterate over the critic Q-function to select actions, so we do not have to iterate over the set of actions – we just use the policy. As such, this will still extend to continuous and large state spaces and be more efficient for large action space.
Implementation
To implement the Q Actor Critic framework, we first create a new base class called ActorCritic, which can be used as a base for other types of actor critic methods, such as advantage actor critics, which we will not discuss here.
The ActorCritic class is an abstract class that looks similar to that of QLearning, except that we update both the actor and the critic:
from itertools import count
from model_free_learner import ModelFreeLearner
class ActorCritic(ModelFreeLearner):
def __init__(self, mdp, actor, critic):
self.mdp = mdp
self.actor = actor # Actor (policy based) to select actions
self.critic = critic # Critic (value based) to evaluate actions
def execute(self, episodes=100, max_episode_length=float('inf')):
episode_rewards = []
for episode in range(episodes):
actions = []
states = []
rewards = []
next_states = []
dones = []
episode_reward = 0
state = self.mdp.get_initial_state()
#step = 0
for step in count():
#while not self.mdp.is_terminal(state):
action = self.actor.select_action(state, self.mdp.get_actions(state))
(next_state, reward, done) = self.mdp.execute(state, action)
self.update_critic(reward, state, action, next_state)
# Store the information from this step of the trajectory
states.append(state)
actions.append(action)
rewards.append(reward)
next_states.append(next_state)
dones.append(done)
state = next_state
episode_reward += reward * (self.mdp.discount_factor ** step)
if done or step == max_episode_length:
break
#step += 1
self.update_actor(rewards, states, actions, next_states, dones)
episode_rewards.append(episode_reward)
return episode_rewards
""" Update the actor using a batch of rewards, states, actions, and next states """
def update_actor(self, rewards, states, actions, next_states, dones):
abstract
""" Update the critc using a reward, state, action, and next state """
def update_critic(self, reward, state, action, next_state):
abstract
Note from the code above that we use the actor (the policy) to choose an action, and then update both the critic and the actor. In this particular implementation, we batch update the actor policy at the end of the episode.
Next, we have to instantite the ActorCritic class as a QActorCritic class to implement the update_actor and update_critic classes:
from actor_critic import ActorCritic
class QActorCritic(ActorCritic):
def __init__(self, mdp, actor, critic):
super().__init__(mdp, actor, critic)
def update_actor(self, rewards, states, actions, next_states, dones):
q_values = self.critic.get_q_values(states, actions)
next_state_q_values = self.critic.get_q_values(next_states, actions)
deltas = [
reward + (self.mdp.get_discount_factor() * next_state_q_value) - q_value
if not done else (reward - q_value)
for reward, next_state_q_value, q_value, done in zip(
rewards, next_state_q_values, q_values, dones
)
]
self.actor.update(states, actions, deltas)
def update_critic(self, reward, state, action, next_state):
state_value = self.critic.get_q_value(state, action)
actions = self.mdp.get_actions(next_state)
next_state_value = self.critic.get_max_q(next_state, actions)
delta = reward + self.mdp.get_discount_factor() * next_state_value - state_value
self.critic.update(state, action, delta)
Now, we can create a policy and Q-function using any differentiable policy and any Q-function implementation. We choose DeepNeuralNetworkPolicy and DeepQFunction with QLearning updates.
from deep_nn_policy import DeepNeuralNetworkPolicy
from q_actor_critic import QActorCritic
from deep_q_function import DeepQFunction
from gridworld import GridWorld
from multi_armed_bandit.epsilon_greedy import EpsilonGreedy
from qlearning import QLearning
mdp = GridWorld()
action_space = len(mdp.get_actions())
state_space = len(mdp.get_initial_state())
# Instantiate the critic
critic = DeepQFunction(state_space, action_space, hidden_dim=16)
# Instantiate the actor
actor = DeepNeuralNetworkPolicy(state_space, action_space)
# Instantiate the actor critic agent
learner = QActorCritic(mdp, actor, critic)
episode_rewards = learner.execute(episodes=300)
mdp.visualise_stochastic_policy(actor)
mdp.visualise_q_function(critic)
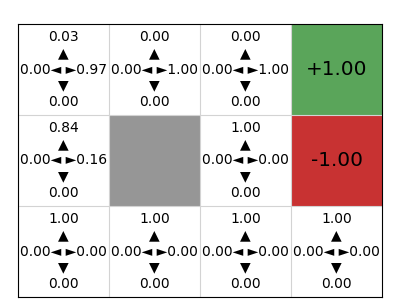
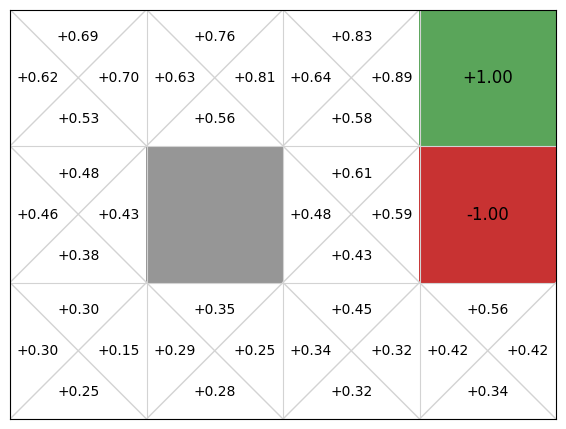
We can see that the actor critic agent has learnt both a policy that is very good, but also a Q-function critic that could be used as a policy (because our action space is finite and very small). In a continuous state space, we would be able to learn the critic, but not use it as a policy because we cannot iterate over the possible actions.
Takeaways
- Like REINFORCE, actor-critic methods are policy-gradient based, so directly learn a policy instead of first learning a value function or Q-function.
- Actor-critic methods also learn a value function or Q-function to reduce the variance in the cumulative rewards.
