
Learning outcomes
The learning outcomes of this chapter are:
- Apply policy gradients and actor critic methods to solve small-scale MDP problems manually and program policy gradients and actor critic algorithms to solve medium-scale MDP problems automatically.
- Compare and contrast policy-based reinforcement learning with value-based reinforcement learning.
Overview
As noted earlier, policy-based methods search for a policy directly, rather than searching for a value function and extracting a policy. In this section, we look at a model-free method that optimises a policy directly. It is similar to Q-learning and SARSA, but instead of updating a Q-function, it updates the parameters [latex]\theta[/latex] of a policy directly using gradient ascent.
In policy gradient methods, we approximate the policy from the rewards and actions received in our episodes, similar to the way we do it with Q-learning. We can do this provided that the policy has two properties:
- The policy is represented using some function that is differentiable with respect to its parameters. For a non-differentiable policy, we cannot calculate the gradient.
- Typically, we want the policy to be stochastic. Recall from the section on policies that a stochastic policy specifies a probability distribution over actions, defining the probability with which each action should be chosen.
The goal of a policy gradient is to approximate the optimal policy [latex]\pi_{\theta}(s, a)[/latex] via gradient ascent on the expected return. Gradient ascent will find the best parameters [latex]\theta[/latex] for the particular MDP.
Policy improvement using gradient ascent
The goal of gradient ascent is to find weights of a policy function that maximises the expected return. This is done iteratively by calculating the gradient from some data and updating the weights of the policy.
The expected value of a policy [latex]\pi_{\theta}[/latex] with parameters [latex]\theta[/latex] is defined as:
[latex]J(\theta) = V^{\pi_{\theta}}(s_0)[/latex]
where [latex]V^{\pi_{\theta}}[/latex] is the policy evaluation using the policy [latex]\pi_{\theta}[/latex] and [latex]s_0[/latex] is the intial state. This expression is computationally expensive to calculate, because we need to execute every possible episode from [latex]s_0[/latex] to every terminal state, which may be an infinite number of episodes. So, we use policy gradient algorithms to approximate this instead. These search for a local maximum in [latex]J(\theta)[/latex] by ascending the gradient of the policy with respect to the parameters [latex]\theta[/latex], using episodic samples.
Definition – Policy gradient
Given a policy objective [latex]J(\theta)[/latex], the policy gradient of [latex]J[/latex] with respect to [latex]\theta[/latex], written [latex]\nabla_{\theta}J(\theta)[/latex] is defined as:
\nabla_{\theta}J(\theta) = \begin{pmatrix} \frac{\partial J(\theta)}{\partial \theta_1} \\ \vdots \\ \frac{\partial J(\theta)}{\partial \theta_n} \end{pmatrix}
\end{split}\]
where [latex]\frac{\partial J(\theta)}{\partial \theta_i}[/latex] is the partial derivative of [latex]J[/latex] with respective to [latex]\theta_i[/latex].
If we want to follow the gradient towards the optimal [latex]J(\theta)[/latex] for our problem, we use the gradient and update the weights:
[latex]\theta \leftarrow \theta + \alpha \nabla J(\theta)[/latex]
where [latex]\alpha[/latex] is a learning rate parameter that dictates how big the step in the direction of the gradient should be.
The question is: what is [latex]\nabla J(\theta)[/latex]? The policy gradient theorem (see Sutton and Barto, Section 13.2) says that for any differentiable policy [latex]\pi_{\theta}[/latex], state [latex]s[/latex], and action [latex]a[/latex], that [latex]\nabla J(\theta)[/latex] is:
[latex]\nabla J(\theta) = \mathbb{E}[\nabla\ \textrm{ln} \pi_{\theta}(s, a) Q(s,a)][/latex]
The expression [latex]\textrm{ln} \pi_{\theta}(s, a)[/latex] tells us how to change the weights [latex]\theta[/latex]: increase the log probability of selecting action [latex]a[/latex] in state [latex]s[/latex]. If the quality of selecting action [latex]a[/latex] in [latex]s[/latex] is positive, we would increase that probability; otherwise we decrease the probability.
So, this is the expected return of taking action [latex]\pi_{\theta}(s,a)[/latex] multiplied by the gradient.
In these notes, we will not go into details about gradients or algorithms for solving them – this is itself a large topic that is relevant outside of reinforcement learning. Instead, we will just give the intuition and how to use this for model-free reinforcement learning.
REINFORCE
The REINFORCE algorithm is one algorithm for policy gradients. We cannot calculate the gradient optimally because this is too computationally expensive – we would need to solve for all possible trajectories in our model. In REINFORCE, we sample trajectories, similar to the sampling process in Monte-Carlo reinforcement learning.
Algorithm 13 (REINFORCE)
REINFORCE generates an entire episode using Monte-Carlo simulation by following the policy so far; therefore, it generates better and better policies as [latex]\pi[/latex] is improved. It then steps through each action in the episode, a calculates [latex]G[/latex], the total future discounted reward of the trajectory. Using this reward, it calculates the gradient [latex]\pi[/latex] and multiples this in the direction of [latex]G[/latex].
Comparing to value-based techniques, we can see that REINFORCE (and other policy-gradient approaches) do not evaluate each action in the policy improvement process. In policy iteration, we update the policy [latex]\pi(s) \leftarrow \textrm{argmax}_{a \in A(s)} Q^\pi(s,a)[/latex]. In REINFORCE, the most recently sampled action and its reward are used to calculate the gradient and update.
This has the advantage that policy-gradient approaches can be applied when the action space or state space are continuous; e.g. there are one or more actions with a parameter that takes a continuous value. This is because it uses the gradient instead of doing the policy improvement explicitly. For the same reason, policy-gradient approaches are often more efficient than value-based approaches when there are a large number of actions.
Note
From the algorithm above, we can see that REINFORCE is an on policy approach. The sample trajectories from directly from [latex]\pi_{\theta}[/latex] and the update happens
Implementation
The implementation of REINFORCE takes a policy, but this policy must be differentiable. As such, we cannot use the tabular policy used in policy iteration. As we can see, unlike Q-learning and SARSA, the update happens only at the end of each episode.
import random
from itertools import count
class PolicyGradient:
def __init__(self, mdp, policy) -> None:
super().__init__()
self.mdp = mdp
self.policy = policy
""" Generate and store an entire episode trajectory to use to update the policy """
def execute(self, episodes=100, max_episode_length=float('inf')):
total_steps = 0
random_steps = 50
episode_rewards = []
for episode in range(episodes):
actions = []
states = []
rewards = []
state = self.mdp.get_initial_state()
episode_reward = 0.0
for step in count():
if total_steps < random_steps:
action = random.choice(self.mdp.get_actions(state))
else :
action = self.policy.select_action(state, self.mdp.get_actions(state))
(next_state, reward, done) = self.mdp.execute(state, action)
# Store the information from this step of the trajectory
states.append(state)
actions.append(action)
rewards.append(reward)
state = next_state
episode_reward += reward * (self.mdp.discount_factor ** step)
total_steps += 1
if done or step == max_episode_length:
break
deltas = self.calculate_deltas(rewards)
self.policy.update(states, actions, deltas)
episode_rewards.append(episode_reward)
return episode_rewards
def calculate_deltas(self, rewards):
"""
Generate a list of the discounted future rewards at each step of an episode
Note that discounted_reward[T-2] = rewards[T-1] + discounted_reward[T-1] * gamma.
We can use that pattern to populate the discounted_rewards array.
"""
T = len(rewards)
discounted_future_rewards = [0 for _ in range(T)]
# The final discounted reward is the reward you get at that step
discounted_future_rewards[T - 1] = rewards[T - 1]
for t in reversed(range(0, T - 1)):
discounted_future_rewards[t] = (
rewards[t]
+ discounted_future_rewards[t + 1] * self.mdp.get_discount_factor()
)
deltas = []
for t in range(len(discounted_future_rewards)):
deltas += [
(self.mdp.get_discount_factor() ** t)
* discounted_future_rewards[t]
]
return deltas
We need a differentiable policy so that we can calculate the gradient and update. To illustrate this from first principles, let’s look at an implementation of a policy that uses logistic regression. This basic implementation supports environments with only two actions, but it is sufficient to illustrate the basics of policy gradient methods from first principles.
The policy inherits from StochasticPolicy, which means that the policy is a stochastic policy [latex]\pi_{\theta}(s,a)[/latex] that returns the probability of action [latex]a[/latex] being executed in state [latex]s[/latex]. The select_action is stochastic, as can be seen below – it selects between the two actions using the policies probability distribution.
import math
import random
from policy import StochasticPolicy
""" A two-action policy implemented using logistic regression from first principles """
class LogisticRegressionPolicy(StochasticPolicy):
""" Create a new policy, with given parameters theta (randomly if theta is None)"""
def __init__(self, actions, num_params, alpha=0.1, theta=None):
assert len(actions) == 2
self.actions = actions
self.alpha = alpha
if theta is None:
theta = [0.0 for _ in range(num_params)]
self.theta = theta
""" Select one of the two actions using the logistic function for the given state """
def select_action(self, state, actions):
# Get the probability of selecting the first action
probability = self.get_probability(state, self.actions[0])
# With a probability of 'probability' take the first action
if random.random() < probability:
return self.actions[0]
return self.actions[1]
""" Update our policy parameters according using the gradient descent formula:
theta <- theta + alpha * G * nabla J(theta),
where G is the future discounted reward
"""
def update(self, states, actions, deltas):
for t in range(len(states)):
gradient_log_pi = self.gradient_log_pi(states[t], actions[t])
# Update each parameter
for i in range(len(self.theta)):
self.theta[i] += self.alpha * deltas[t] * gradient_log_pi[i]
""" Get the probability of applying an action in a state """
def get_probability(self, state, action):
# Calculate y as the linearly weight product of the
# policy parameters (theta) and the state
y = self.dot_product(state, self.theta)
# Pass y through the logistic regression function to convert it to a probability
probability = self.logistic_function(y)
if action == self.actions[0]:
return probability
return 1 - probability
""" Computes the gradient of the log of the policy (pi),
which is needed to get the gradient of the objective (J).
Because the policy is a logistic regression, using the policy parameters (theta).
pi(actions[0] | state)= 1 / (1 + e^(-theta * state))
pi(actions[1] | state) = 1 / (1 + e^(theta * state))
When we apply a logarithmic transformation and take the gradient we end up with:
grad_log_pi(left | state) = state - state * pi(left | state)
grad_log_pi(right | state) = - state * pi(right | state)
"""
def gradient_log_pi(self, state, action):
y = self.dot_product(state, self.theta)
if action == self.actions[0]:
return [s_i - s_i * self.logistic_function(y) for s_i in state]
return [-s_i * self.logistic_function(y) for s_i in state]
""" Standard logistic function """
@staticmethod
def logistic_function(y):
return 1 / (1 + math.exp(-y))
""" Compute the dot product between two vectors """
@staticmethod
def dot_product(vec1, vec2):
return sum([v1 * v2 for v1, v2 in zip(vec1, vec2)])
The update method, as well as the gradient_log_pi method that it calls, are where the policy gradient theorem is applied. In update, for every state-action transition in the trajectory, we calculate the gradient and then update the parameters [latex]\theta[/latex] using the corresponding partial derivative.
Because we use logistic regression to represent the policy in this simplified implementation that allows only two actions, the probability for each action (and therefore the policy) can be calculated as follows:
\begin{aligned}
\pi_{\theta}(s, a_0) &= \frac{1}{1 + e^{-\theta \cdot s}}\\
\pi_{\theta}(s, a_1) &= \frac{1}{1 + e^{\theta \cdot s}}
\end{aligned}
\end{split}\]
This gives us the probability of choosing actions [latex]a_0[/latex] and [latex]a_1[/latex] in state [latex]s[/latex], which approximates the expression [latex]\pi_{\theta}(s, a) Q(s,a)[/latex] in the policy gradient theorem.
Since the policy follows a sigmoid function, we can use the following result from calculus to find the derivative. If [latex]\sigma(x)[/latex] is a sigmoid, then the derivative of [latex]\sigma(x)[/latex] with respect to [latex]x[/latex] conforms to the following pattern:
\begin{aligned}
\sigma(x) &= \frac{1}{1 + e^{\theta \cdot x}}\\[1mm]
\frac{\partial \sigma(x)}{\partial x} &= \sigma(x)(1 – \sigma(x))
\end{aligned}
\end{split}\]
Using this result, we can then find [latex]\nabla \textrm{ln} \pi(a, s)[/latex]:
\begin{aligned}
\nabla \textrm{ln} \pi_{\theta}(s, a_0) &= s – s\cdot \pi_{\theta}(s, a_0)\\[1mm]
\nabla \textrm{ln} \pi_{\theta}(s, a_1) &= -s \cdot \pi_{\theta}(s, a_1)
\end{aligned}
\end{split}\]
This gives us a vector of the partial derivatives, which the update method then uses to update the corresponding [latex]\theta_i[/latex] value.
Let’s try this implementation on an example using the REINFORCE algorithm and our logistic regression policy. Because our logistic regression policy supports only two actions, we cannot use the 4×3 GridWorld example, so we instead use an even simpler example (who thought that would be possible!) of a Gridword that is 11×1 and has a -1 reward at one end and a +1 reward at the other:
from gridworld import GridWorld
from gridworld import OneDimensionalGridWorld
from policy_gradient import PolicyGradient
from logistic_regression_policy import LogisticRegressionPolicy
gridworld = GridWorld(
height=1, width=11, initial_state=(5, 0), goals=[((0, 0), -1), ((10, 0), 1)]
)
gridworld_image = gridworld.visualise()

Next, we create a LogisticRegressionPolicy with just two actions, left and right, and with two parameters corresponding to the [latex]x[/latex] and [latex]y[/latex] coordinates. This is used in a PolicyGradient instance to produce the following policy:
policy = LogisticRegressionPolicy(
actions=[GridWorld.LEFT, GridWorld.RIGHT],
num_params=len(gridworld.get_initial_state()),
)
PolicyGradient(gridworld, policy).execute(episodes=100)
policy_image = gridworld.visualise_stochastic_policy(policy)

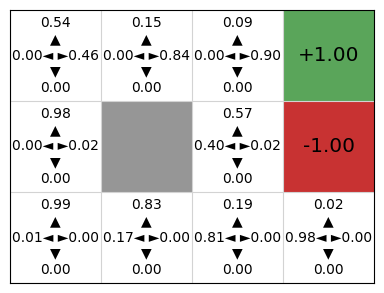
We can see here that this is a stochastic policy — instead of giving us an action (left or right) in each cell, we get the probability that the policy will select each of these actions. The policy learns to select right with a much higher probability because the positive reward is to the right.
To follow the policy, we can use this deterministically by simply selecting the action with the highest probability, but in some applications, the optimal behaviour is to select an action by sampling from the probability distribution.
The difference between value-based methods such as Q-learning and SARSA is demonstrated by the output: there is just a policy and no value function or Q-function because the policy is learnt directly.
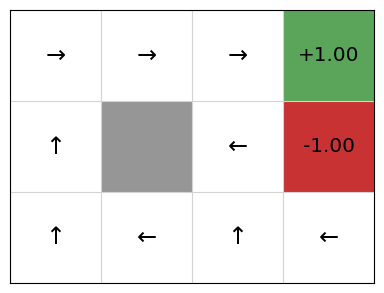
If we step through the policy during training, we can see the gradient updates performing their role in policy improvement:

This policy only considers two actions, but it can be easily extended to support multiple actions using standard machine learning techniques like one-vs-rest classification.
Deep REINFORCE
Just like we can use deep neural networks to approximate Q-functions in deep Q learning, we can use deep neural networks to approximate policies. Neural networks are differentiable, so these can be used in policy gradient algorithms such as REINFORCE — the policy parameters [latex]\theta[/latex] are the parameters to the neural network.
As with deep Q learning, this has the advantage that features of the problem are learnt, features do not have to be independent, therefore supporting a larger set of problems compared to a logistic regression approach, and we can use unstructured data as input, such as images and videos.
To implement a deep policy gradient approach in REINFORCE, we just have to implement a new policy that uses a deep neural network.
In our implementation, we again use the PyTorch deep learning framework (https://pytorch.org/).
The policy uses a three layer network with the following:
- The first layer takes the state vector, so the input features are the features of the state. In the case of the GridWorld example, this would be just the x- and y-coordinates of the agent.
- We have a hidden layer, with a default number of 64 hidden dimensions, but this is parameterised by the variable
hidden_dimin the__init__constructor. - The third and final layer is the output layer, which returns a categorical distribution with a dimensionality the same size as the action space, so that each action is associated with a probability of being selected.
- We use a non-linear ReLU (rectified linear unit) between layers.
Recall from the section on deep Q learning that the Linear layers are dense layers in PyTorch.
It inherits from the StochasticPolicy and then implement the update, select_action, and get_probability methods. These take advantage of optimisations with the PyTorch framework, so the calculation of the gradient is ‘hidden’ by the PyTorch library. The line self.optimiser.zero_grad() then ‘zeros’ out the existing gradient so that the new gradient can be calculated. The gradient is calculated using loss.backwards(). Then self.optimiser.step() adjusts the parameters [latex]\theta[/latex] in the direction of the gradient:
import torch
import torch.nn as nn
from torch.distributions.categorical import Categorical
from torch.optim import Adam
import torch.nn.functional as F
from policy import StochasticPolicy
class DeepNeuralNetworkPolicy(StochasticPolicy):
"""
An implementation of a policy that uses a PyTorch (https://pytorch.org/)
deep neural network to represent the underlying policy.
"""
def __init__(self, state_space, action_space, hidden_dim=64, alpha=0.001, stochastic=True):
self.state_space = state_space
self.action_space = action_space
self.temperature = 6.0
# Define the policy structure as a sequential neural network.
self.policy_network = nn.Sequential(
nn.Linear(in_features=self.state_space, out_features=hidden_dim),
nn.ReLU(),
nn.Linear(in_features=hidden_dim, out_features=hidden_dim),
nn.ReLU(),
nn.Linear(in_features=hidden_dim, out_features=self.action_space),
)
# Initialize weights using Xavier initialization and biases to zero
#self._initialize_weights()
# The optimiser for the policy network, used to update policy weights
self.optimiser = Adam(self.policy_network.parameters(), lr=alpha)
# Whether to select an action stochastically or deterministically
self.stochastic = stochastic
def _initialize_weights(self):
for layer in self.policy_network:
if isinstance(layer, nn.Linear):
nn.init.xavier_uniform_(layer.weight)
nn.init.zeros_(layer.bias)
# Ensure the last layer outputs logits close to zero
last_layer = self.policy_network[-1]
if isinstance(last_layer, nn.Linear):
with torch.no_grad():
last_layer.weight.fill_(0)
last_layer.bias.fill_(0)
""" Select an action using a forward pass through the network """
def select_action(self, state, actions):
# Convert the state into a tensor so it can be passed into the network
state = torch.as_tensor(state, dtype=torch.float32)
action_logits = self.policy_network(state)
# Mark out the actions that are unavailable
mask = torch.full_like(action_logits, float('-inf'))
mask[actions] = 0
masked_logits = action_logits + mask
action_distribution = Categorical(logits=masked_logits)
if self.stochastic:
# Sample an action according to the probability distribution
action = action_distribution.sample()
else:
# Choose the action with the highest probability
action_probabilities = torch.softmax(masked_logits, dim=-1)
action = torch.argmax(action_probabilities)
return action.item()
""" Get the probability of an action being selected in a state """
def get_probability(self, state, action):
state = torch.as_tensor(state, dtype=torch.float32)
with torch.no_grad():
action_logits = self.policy_network(state)
# A softmax layer turns action logits into relative probabilities
probabilities = F.softmax(input=action_logits, dim=-1).tolist()
# Convert from a tensor encoding back to the action space
return probabilities[action]
def evaluate_actions(self, states, actions):
action_logits = self.policy_network(states)
action_distribution = Categorical(logits=action_logits)
log_prob = action_distribution.log_prob(actions.squeeze(-1))
return log_prob.view(1, -1)
def update(self, states, actions, deltas):
# Convert to tensors to use in the network
deltas = torch.as_tensor(deltas, dtype=torch.float32)
states = torch.as_tensor(states, dtype=torch.float32)
actions = torch.as_tensor(actions)
action_log_probs = self.evaluate_actions(states, actions)
# Construct a loss function, using negative because we want to descend,
# not ascend the gradient
loss = -(action_log_probs * deltas).sum()
self.optimiser.zero_grad()
loss.backward()
# Take a gradient descent step
self.optimiser.step()
def save(self, filename):
torch.save(self.policy_network.state_dict(), filename)
@classmethod
def load(cls, state_space, action_space, filename):
policy = cls(state_space, action_space)
policy.policy_network.load_state_dict(torch.load(filename))
return policy
As with the deep Q learning implementation, PyTorch does not support strings as values, so we need to encode action names and states as integers.
We can now use this implementation by creating a REINFORCE agent with a DeepNeuralNetworkPolicy instance as the policy, and use it to learn a policy for the GridWorld example:
from gridworld import GridWorld
from policy_gradient import PolicyGradient
from deep_nn_policy import DeepNeuralNetworkPolicy
gridworld = GridWorld()
state_space = len(gridworld.get_initial_state())
action_space = len(gridworld.get_actions())
policy = DeepNeuralNetworkPolicy(state_space, action_space)
PolicyGradient(gridworld, policy).execute(episodes=1000)
gridworld_image = gridworld.visualise_stochastic_policy(policy)
gridworld.visualise_policy(policy)
Again, we can see that this policy is stochastic: each action has a probability of being executed in a state.
Simulating the process of training the policy, we can see that initially, all four actions have (approximately) the same probability of being executed, but deep REINFORCE learns a good Q-function and therefore policy:
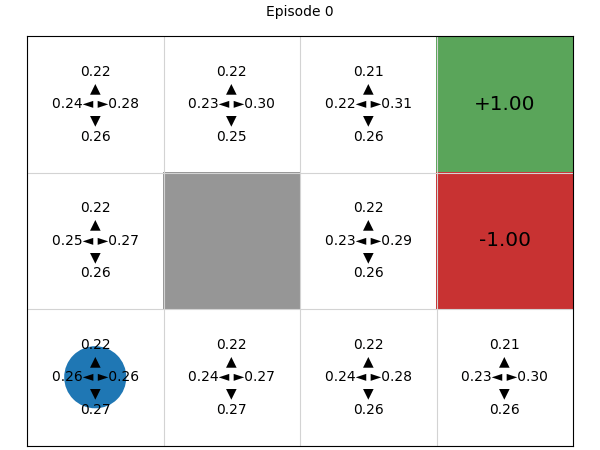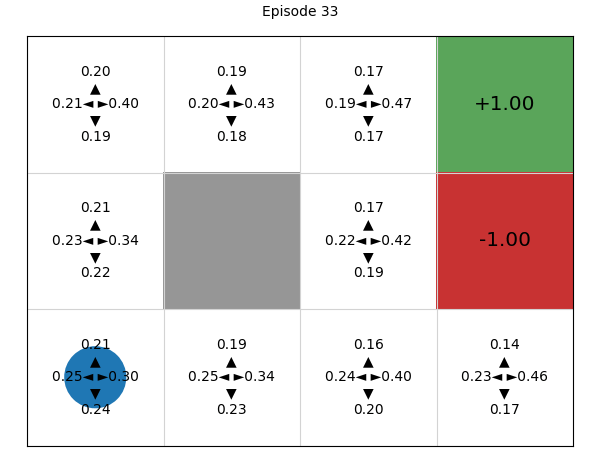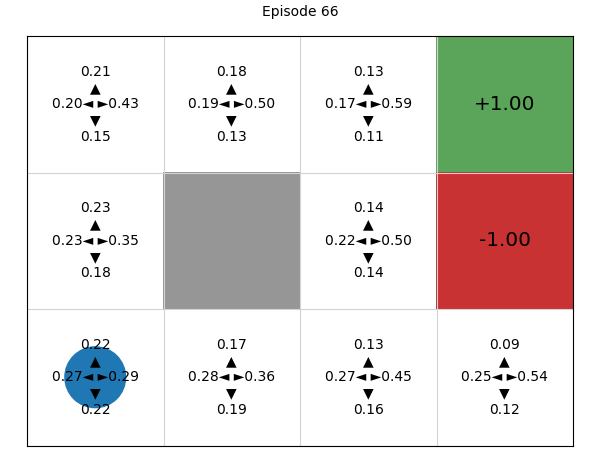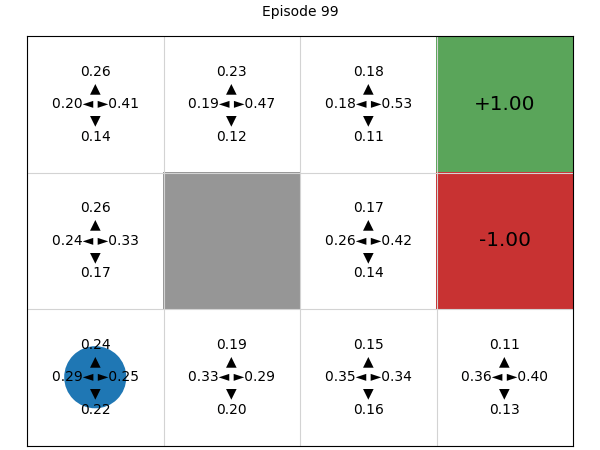
Advantages and disadvantages of policy gradients (compared to value-based techniques)
Advantages
- High-dimensional problems: The major advantage of policy-gradient approaches compared to value-based techniques like Q-learning and SARSA is that they can handle high-dimensional action and state spaces, including actions and states that are continuous. This is because we do not have to iterate over all actions using [latex]\textrm{argmax}_{a \in A(s)}[/latex] as we do in value-based approaches. For continuous problems, [latex]\textrm{argmax}_{a \in A(s)}[/latex] is not possible to calculate, while for a high number of actions, the computational complexity is dependent on the number of actions.
Disadvantages
- Sample inefficiency: Since the policy gradients algorithm takes an entire episode to do the update, it is difficult to determine which of the state-action pairs are those that effect the value [latex]G[/latex] (the episode reward), and therefore which to sample.
- Loss of explainability: Model-free reinforcement learning is a particularly challenging case to understand and explain why a policy is making a decision. This is largely due to the model-free property: there are no action definitions that can used as these are unknown. However, policy gradients are particularly difficult because the values of states are unknown: we just have a resulting policy. With value-based approaches, knowing [latex]V[/latex] or [latex]Q[/latex] provides some insight into why actions are chosen by a policy; although explainability problems still remain.
Takeaways
- Policy gradient methods such as REINFORCE directly learn a policy instead of first learning a value function or Q-function.
- Using trajectories, the parameters for a policy are updated by following the gradient upwards – the same as gradient descent but in the opposite direction.
- Unlike policy iteration, policy gradient approaches are model free.
