
Learning outcomes
The learning outcomes of this chapter are:
- Apply policy iteration to solve small-scale MDP problems manually and program policy iteration algorithms to solve medium-scale MDP problems automatically.
- Discuss the strengths and weaknesses of policy iteration.
- Compare and contrast policy iteration to value iteration.
Overview
The other common way that MDPs are solved is using policy iteration – an approach that is similar to value iteration. While value iteration iterates over value functions, policy iteration iterates over policies themselves, creating a strictly improved policy in each iteration (except if the iterated policy is already optimal).
Policy iteration first starts with some (non-optimal) policy, such as a random policy, and then calculates the value of each state of the MDP given that policy — this step is called policy evaluation. It then updates the policy itself for every state by calculating the expected reward of each action applicable from that state.
The basic idea here is that policy evaluation is easier to computer than value iteration because the set of actions to consider is fixed by the policy that we have so far.
Policy evaluation
An important concept in policy iteration is policy evaluation, which is an evaluation of the expected reward of a policy.
The expected reward of policy [latex]\pi[/latex] from [latex]s[/latex], [latex]V^\pi(s)[/latex], is the weighted average of reward of the possible state sequences defined by that policy times their probability given [latex]\pi[/latex].
Definition – Policy evaluation
Policy evaluation can be characterised as [latex]V^{\pi}(s)[/latex] as defined by the following equation:
[latex]V^\pi(s) = \sum_{s' \in S} P_{\pi(s)} (s' \mid s)\ [r(s,a,s') + \gamma\ V^\pi(s') ][/latex]
where [latex]V^\pi(s)=0[/latex] for terminal states.
Note that this is very similar to the Bellman equation, except [latex]V^\pi(s)[/latex] is not the value of the best action, but instead just as the value for [latex]\pi(s)[/latex], the action that would be chosen in [latex]s[/latex] by the policy [latex]\pi[/latex]. Note the expression [latex]P_{\pi(s)}(s' \mid s)[/latex] instead of [latex]P_a(s' \mid s)[/latex], which means we only evaluate the action that the policy defines.
Once we understand the definition of policy evaluation, the implementation is straightforward. It is the same as value iteration except that we use the policy evaluation equation instead of the Bellman equation.
Algorithm 11 (Policy evaluation)
The optimal expected reward [latex]V^*(s)[/latex] is [latex]\max_{\pi} V^\pi(s)[/latex] and the optimal policy is [latex]\textrm{argmax}_{\pi} V^\pi(s)[/latex].
Policy improvement
If we have a policy and we want to improve it, we can use policy improvement to change the policy (that is, change the actions recommended for states) by updating the actions it recommends based on [latex]V(s)[/latex] that we receive from the policy evaluation.
Let [latex]Q^{\pi}(s,a)[/latex] be the expected reward from [latex]s[/latex] when doing [latex]a[/latex] first and then following the policy [latex]\pi[/latex]. Recall from the chapter on Markov Decision Processes that we define define this as:
[latex]Q^{\pi}(s,a) = \sum_{s' \in S} P_a(s' \mid s)\ [r(s,a,s') \, + \, \gamma\ V^{\pi}(s')][/latex]
In this case, [latex]V^{\pi}(s')[/latex] is the value function from the policy evaluation.
If there is an action [latex]a[/latex] such that [latex]Q^{\pi}(s,a) > Q^{\pi}(s,\pi(s))[/latex], then the policy [latex]\pi[/latex] can be strictly improved by setting [latex]\pi(s) \leftarrow a[/latex]. This will improve the overall policy.
Policy iteration
Pulling together policy evaluation and policy improvement, we can define policy iteration, which computes an optimal [latex]\pi[/latex] by performing a sequence of interleaved policy evaluations and improvements:
Algorithm 12 (Policy iteration)
The policy iteration algorithm finishes with an optimal [latex]\pi[/latex] after a finite number of iterations, because the number of policies is finite, bounded by [latex]O(|A|^{|S|})[/latex], unlike value iteration, which can theoretically require infinite iterations.
However, each iteration costs [latex]O(|S|^2 |A| + |S|^3)[/latex]. Empirical evidence suggests that the most efficient is dependent on the particular MDP model being solved, but that surprisingly few iterations are often required for policy iteration.
Implementation
Below is a Python implementation for policy iteration. In this implementation, the parameter max_iterations is the maximum number of iterations of the policy iteration, and the parameter theta the largest amount the value function corresponding to the current policy can change before the policy evaluation look terminates.
from tabular_policy import TabularPolicy
from tabular_value_function import TabularValueFunction
from qtable import QTable
class PolicyIteration:
def __init__(self, mdp, policy):
self.mdp = mdp
self.policy = policy
def policy_evaluation(self, policy, values, theta=0.001):
while True:
delta = 0.0
new_values = TabularValueFunction()
for state in self.mdp.get_states():
# Calculate the value of V(s)
actions = self.mdp.get_actions(state)
old_value = values.get_value(state)
new_value = values.get_q_value(
self.mdp, state, policy.select_action(state, actions)
)
values.update(state, new_value)
delta = max(delta, abs(old_value - new_value))
# terminate if the value function has converged
if delta < theta:
break
return values
""" Implmentation of policy iteration iteration. Returns the number of iterations executed """
def policy_iteration(self, max_iterations=100, theta=0.001):
# create a value function to hold details
values = TabularValueFunction()
for i in range(1, max_iterations + 1):
policy_changed = False
values = self.policy_evaluation(self.policy, values, theta)
for state in self.mdp.get_states():
actions = self.mdp.get_actions(state)
old_action = self.policy.select_action(state, actions)
q_values = QTable(alpha=1.0)
for action in self.mdp.get_actions(state):
# Calculate the value of Q(s,a)
new_value = values.get_q_value(self.mdp, state, action)
q_values.update(state, action, new_value)
# V(s) = argmax_a Q(s,a)
new_action = q_values.get_argmax_q(state, self.mdp.get_actions(state))
self.policy.update(state, new_action)
policy_changed = (
True if new_action is not old_action else policy_changed
)
if not policy_changed:
return i
return max_iterations
From this, we can see that policy evaluation looks very similar to value iteration. The main differences is in the inner loop: instead of finding the action with the maximum Q-value, we simply find the value of the action that is given the policy: policy.select_action(state).
We can execute this to get the policy:
from gridworld import GridWorld
from policy_iteration import PolicyIteration
from tabular_policy import TabularPolicy
gridworld = GridWorld()
policy = TabularPolicy(default_action=gridworld.LEFT)
PolicyIteration(gridworld, policy).policy_iteration(max_iterations=100)
gridworld.visualise_policy(policy)
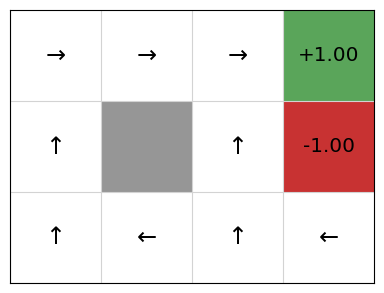
We can see that this matches the optimal policy according to value iteration.
Let’s look at the policies that are generated after each iteration, noting that the initial policy is defined by taking a random action (left) and using that for every state:
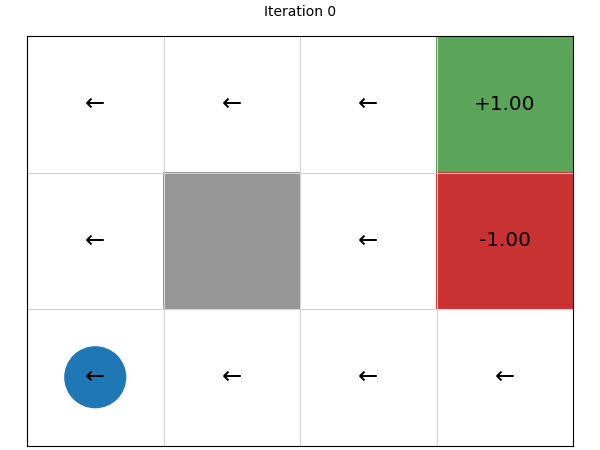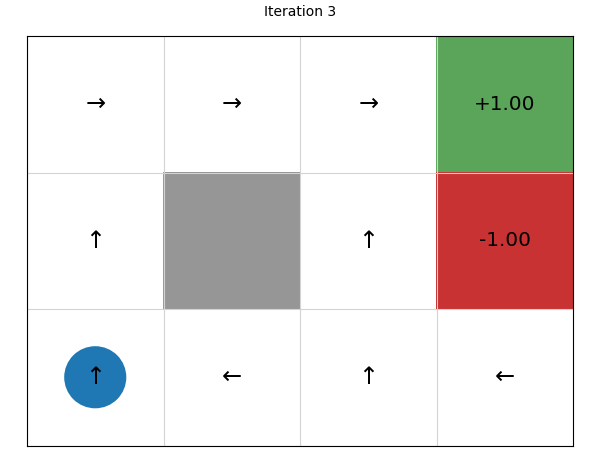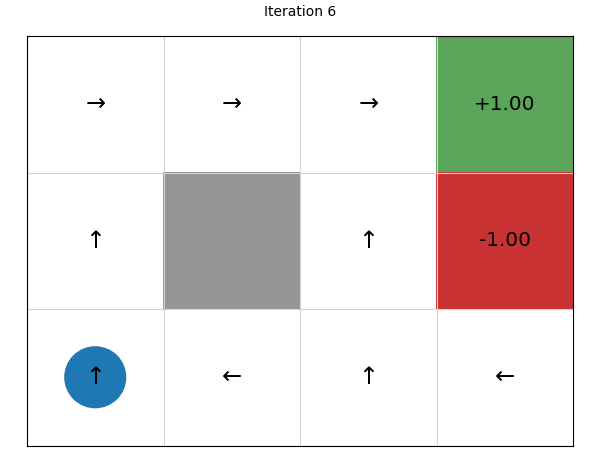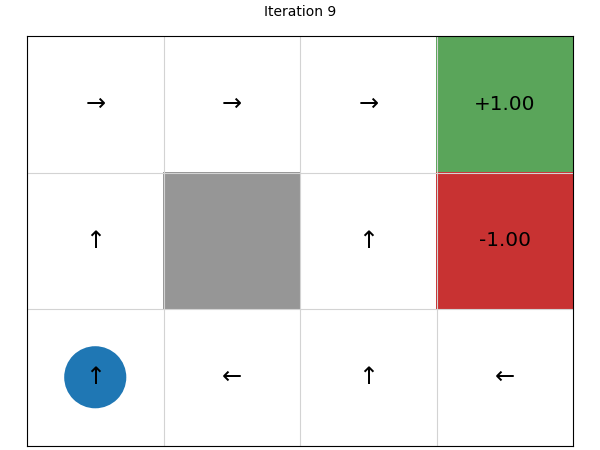
We can see that this converges in just four iterations. Let’s try on a larger state space of a 20 x 15 grid:
gridworld = GridWorld(width=20, height=15)
policy = TabularPolicy(default_action=gridworld.LEFT)
iterations = PolicyIteration(gridworld, policy).policy_iteration(max_iterations=100)
print("Number of iterations until convergence: %d" % (iterations))
gridworld.visualise_policy(policy)
Number of iterations until convergence: 19
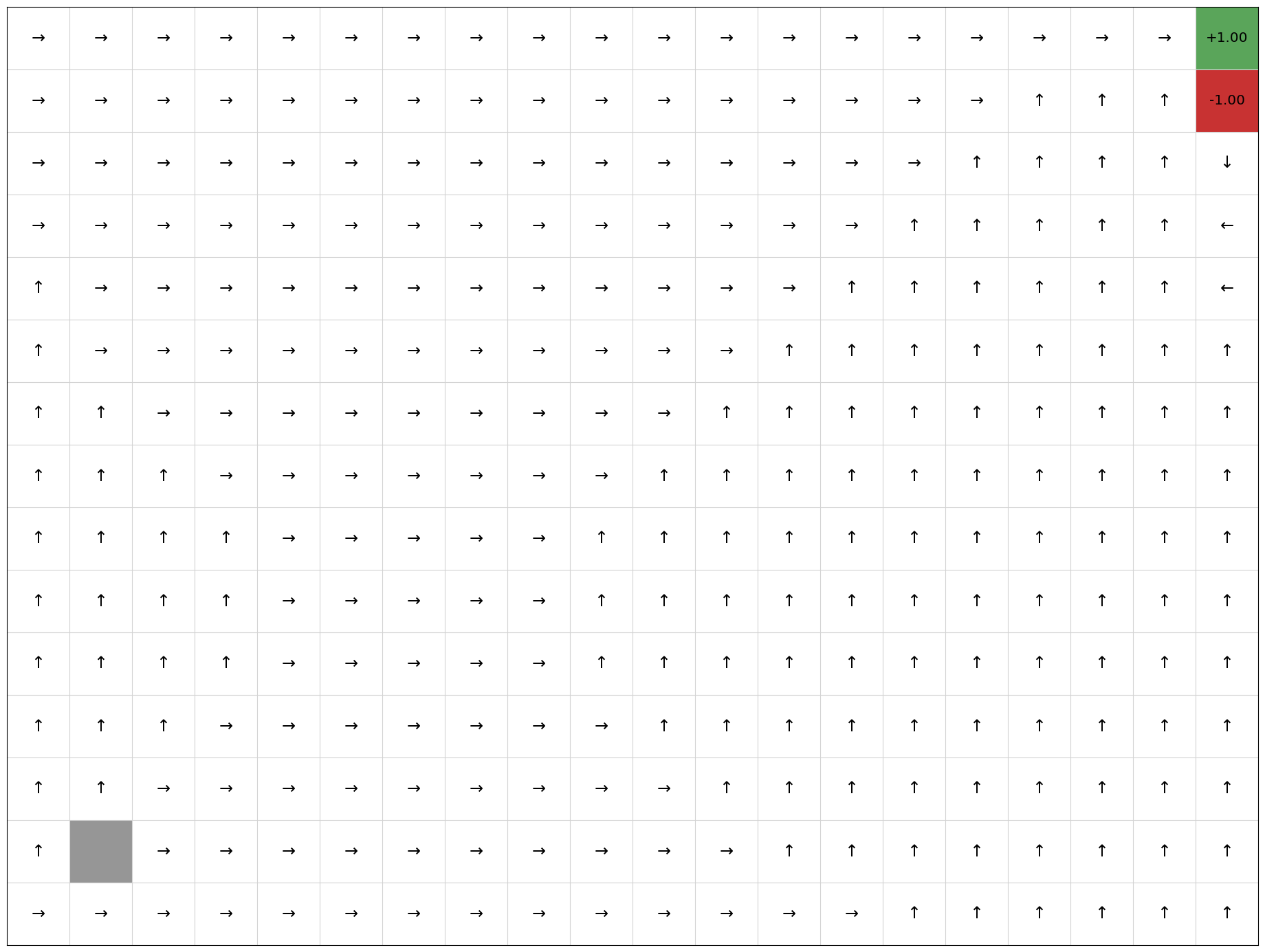
This terminates in 19 iterations. We can see that the policy is optimal as it always directs the agent to terminating state at (3,2) with the positive reward. However, the number of iterations can change depending on the initial policy and the order in which actions are evaluated.
Takeaways
- Policy iteration is a dynamic programming technique for calculating a policy directly, rather than calculating an optimal [latex]V(s)[/latex] and extracting a policy; but one that uses the concept of values.
- It produces an optimal policy in a finite number of steps.
- Similar to value iteration, for medium-scale problems, it works well, but as the state-space grows, it does not scale well.
