
Learning outcomes
The learning outcomes of this chapter are:
- Explain how reward shaping can be used to help model-free
reinforcement learning methods to converge. - Manually apply reward shaping for a given potential function to
solve small-scale MDP problems. - Design and implement potential functions to solve medium-scale MDP
problems automatically. - Compare and contrast reward shaping with Q-value initialisation.
Overview
In the previous chapters, we looked at fundamental temporal difference (TD) methods for reinforcement learning. As noted, these methods have some weaknesses, including that rewards are sometimes sparse. This means that there are few state/actions that lead to non-zero rewards. This is problematic because initially, reinforcement learning algorithms behave entirely randomly and will struggle to find good rewards. Remember the example of a UCT algorithm playing Freeway.
In this section, we look at two simple approaches that can improve temporal difference methods:
- Reward shaping: If rewards are sparse, we can modify/augment our reward function to reward behaviour that we think moves us closer to the solution.
- Q-value Initialisation: We can “guess” good Q-values at the start and initialise [latex]Q(s,a)[/latex] to be this at the start, which will guide our learning algorithm.
Reward shaping
Definition – Reward sharping
Reward shaping is the use of small intermediate ‘fake’ rewards given to the learning agent that help it converge more quickly.
In many applications, you will have some idea of what a good solution should look like. For example, in our simple navigation task, it is clear that moving towards the reward of +1 and away from the reward of -1 are likely to be good solutions.
Can we then speed up learning and/or improve our final solution by nudging our
reinforcement learner towards this behaviour?
The answer is: Yes! We can modify our reinforcement learning algorithm
slightly to give the algorithm some information to help, while also guaranteeing optimality.
This information is known as domain knowledge — that is, stuff about the domain
that the human modeller knows about while constructing the model to be
solved.
Exercise: Freeway What would be a good heuristic for the Freeway game to learn how to get the chicken across the freeway?
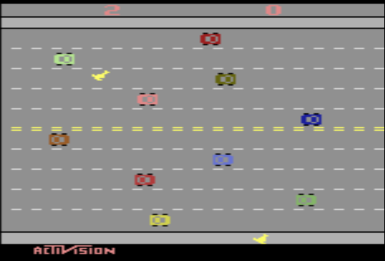
Exercise: GridWorld What would be a good heuristic for GridWorld?
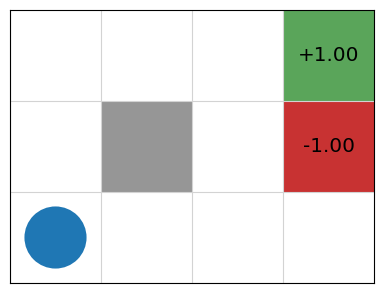
Shaped Reward
In TD learning methods, we update a Q-function when a reward is received. E.g, for 1-step Q-learning:
[latex]Q(s,a) \leftarrow Q(s,a) + \alpha [r + \gamma \max_{a'} Q(s',a') - Q(s,a)][/latex]
The approach to reward shaping is not to modify the reward function or the received reward [latex]r[/latex], but to just give some additional reward for some actions:
[latex]Q(s,a) \leftarrow Q(s,a) + \alpha [r + \underbrace{F(s,s')}_{\text{additional reward}} + \gamma \max_{a'} Q(s',a') - Q(s,a)][/latex]
The purpose of the function is to give an additional reward [latex]F(s,s')[/latex] when any action transitions from state [latex]s[/latex] to state [latex]s'[/latex]. The function [latex]F : S \times S \to \mathbb{R}[/latex] provides heuristic domain knowledge to the problem that is typically manually programmed.
We say that [latex]r + F(s,s')[/latex] is the shaped reward for an action.
Further, we say that [latex]G^{\Phi} = \sum_{i=0}^{\infty} \gamma^i (r_i + F(s_i,s_{i+1}))[/latex] is the shaped reward for the entire episode.
If we define [latex]F(s,s') > 0[/latex] for states [latex]s[/latex] and [latex]s'[/latex], then this provides a small positive reward for transitioning from [latex]s[/latex] to [latex]s'[/latex], thus encouraging actions that transition from [latex]s[/latex] to [latex]s'[/latex] in future exploitation. If we define [latex]F(s,s') < 0[/latex] for states [latex]s[/latex] and [latex]s'[/latex], then this provides a small negative reward for transitioning from [latex]s[/latex] to [latex]s'[/latex], thus discouraging actions that transition like this in future exploitation.
Potential-based Reward Shaping
Potential-based reward shaping is a particular type of reward shaping with nice theoretical guarantees. In potential-based reward shaping, [latex]F[/latex] is of the form:
[latex]F(s,s') = \gamma \Phi(s') - \Phi(s)[/latex]
Example – Potential Reward Shaping for GridWorld
For Grid World, we use the Manhattan distance to define the potential function, normalised by the size of the grid:
[latex]\Phi(s) = 1 - \frac{|x(g) - x(s)| + |y(g) - y(s)|}{width + height - 2}[/latex]
in which [latex]x(s)[/latex] and [latex]y(s)[/latex] return the [latex]x[/latex] and [latex]y[/latex] coordinates of the agent respectively, [latex]g[/latex] is the goal state. and [latex]width[/latex] and [latex]height[/latex] are the width and height of the grid respectively. Note that the coordinates are indexed from 0, so we subtract 2 from the denominator.
Even on the very first iteration, a greedy policy such as [latex]\epsilon[/latex]-greedy, will feedback those states closer to the +1 reward. From state (1,2) with [latex]\gamma=0.9[/latex] if we go Right, we get:
[latex]\begin{split} \begin{array}{lll} F((1,2), (2,2)) & = & \gamma\Phi(2,2) - \Phi(1,2)\\ & = & 0.9 \cdot (1 - \frac{1}{5}) - (1 - \frac{2}{5})\\ & = & 0.12 \end{array} \end{split}[/latex]
We can compare the Q-values for these states for the four different possible moves that could have been taken from (1,2), using and [latex]\alpha=0.1[/latex] and [latex]\gamma=0.9[/latex]:
[latex]\begin{split} \begin{array}{lllcc} \hline \textbf{Action} & r & F(s,s') & \gamma \max_{a'}Q(s',a') & \textrm{New}~ Q(s,a)\\ \hline Up & 0 & 0.9(1 - \frac{2}{5}) - (1 - \frac{2}{5}) = -0.06 & 0 & -0.006\\ Down & 0 & 0.9(1 - \frac{2}{5}) - (1 - \frac{2}{5}) = -0.06 & 0 & -0.006\\ Right & 0 & 0.9(1 - \frac{1}{5}) - (1 - \frac{2}{5}) = \phantom{-}0.12 & 0 & \phantom{-}0.012\\ Left & 0 & 0.9(1 - \frac{3}{5}) - (1 - \frac{2}{5}) = -0.24 & 0 & -0.024\\ \hline \end{array} \end{split}[/latex]
Thus, we can see that our potential reward function rewards actions that go towards the goal and penalises actions that go away from the goal. Recall that state (1,2) is in the top row, so action Up just leaves us in state (1,2) and Down similarly because we cannot go through the walls.
But! It will not always work. Compare states (0,0) and (0,1). Our potential function will reward (0,1) because it is closer to the goal, but we know from from our value iteration example that (0,0) is a higher value state than (0,1). This is because our reward function does not consider the negative reward.
In practice, it is non-trivial to derive a perfect reward function – it is the same problem as deriving the perfect search heuristic. If we could do this, we would not need to even use reinforcement learning – we could just do a greedy search over the reward function.
Implementation
To implement potential-based reward shaping, we need to first implement a potential function. We implement potential functions as subclasses of PotentialFunction. For the GridWorld example, the potential function is 1 minus the normalised distance from the goal:
from potential_function import PotentialFunction
from gridworld import GridWorld
class GridWorldPotentialFunction(PotentialFunction):
def __init__(self, mdp):
self.mdp = mdp
def get_potential(self, state):
if state != GridWorld.TERMINAL:
goal = (self.mdp.width, self.mdp.height)
x = 0
y = 1
return 0.1 * (
1 - ((goal[x] - state[x] + goal[y] - state[y]) / (goal[x] + goal[y]))
)
else:
return 0.0
Reward shaping for Q-learning is then a simple extension of the QLearning class, overriding the get_delta method:
from qlearning import QLearning
class RewardShapedQLearning(QLearning):
def __init__(self, mdp, bandit, potential, qfunction):
super().__init__(mdp, bandit, qfunction=qfunction)
self.potential = potential
def get_delta(self, reward, state, action, next_state, next_action):
q_value = self.qfunction.get_q_value(state, action)
next_state_value = self.state_value(next_state, next_action)
state_potential = self.potential.get_potential(state)
next_state_potential = self.potential.get_potential(next_state)
potential = self.mdp.discount_factor * next_state_potential - state_potential
delta = reward + potential + self.mdp.discount_factor * next_state_value - q_value
return delta
We can run this on a GridWorld example with more states, to make the problem harder::
from qtable import QTable
from qlearning import QLearning
from reward_shaped_qlearning import RewardShapedQLearning
from gridworld_potential_function import GridWorldPotentialFunction
from q_policy import QPolicy
from multi_armed_bandit.epsilon_greedy import EpsilonGreedy
mdp = GridWorld(width = 15, height = 12, goals = [((14,11), 1), ((13,11), -1)])
qfunction = QTable()
potential = GridWorldPotentialFunction(mdp)
RewardShapedQLearning(mdp, EpsilonGreedy(), potential, qfunction).execute(episodes=200)
policy = QPolicy(qfunction)
mdp.visualise_q_function(qfunction)
mdp.visualise_policy(policy)
reward_shaped_rewards = mdp.get_rewards()

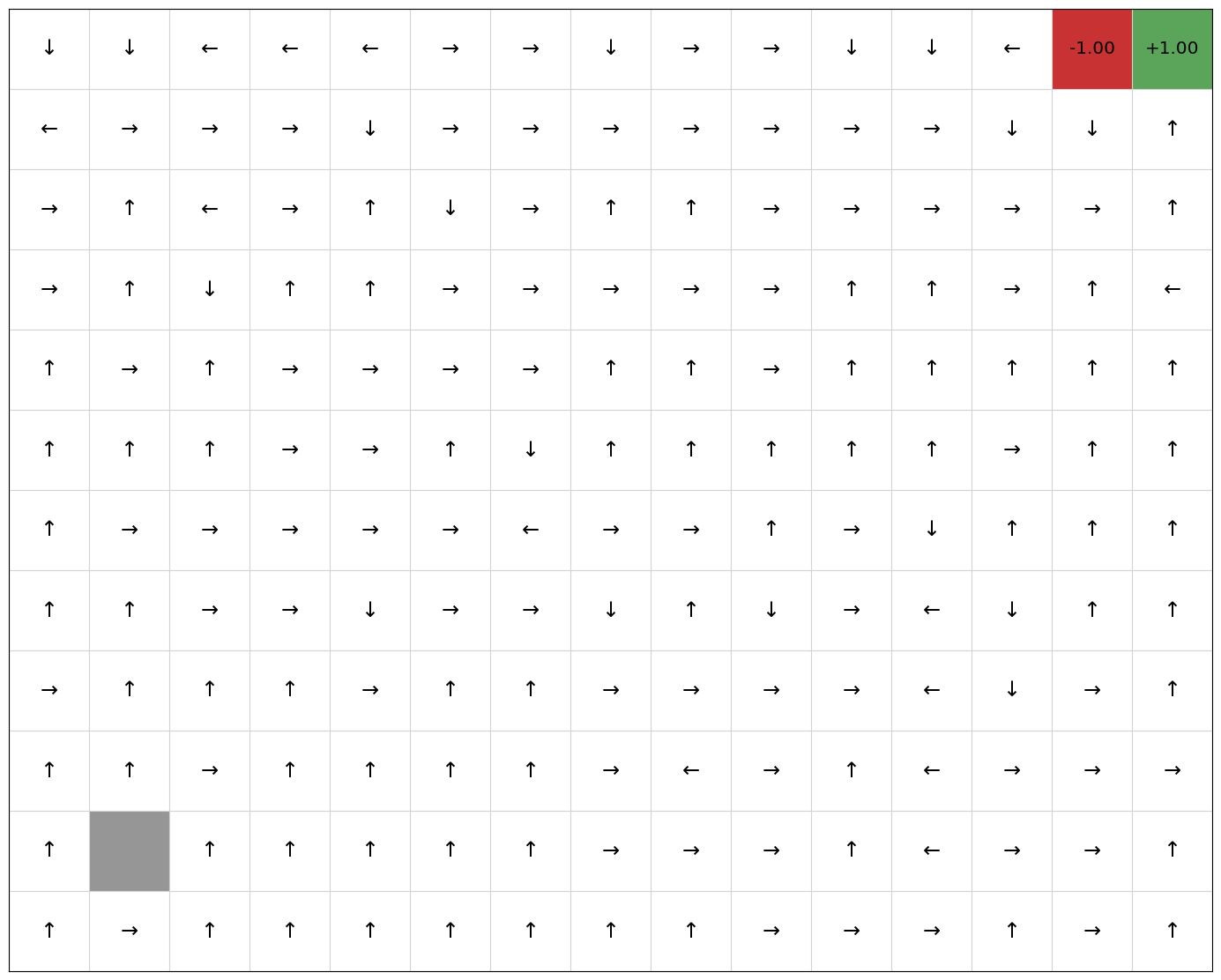
Now, we compare this with Q-learning without reward shaping:
mdp = GridWorld(width = 15, height = 12, goals = [((14,11), 1), ((13,11), -1)])
qfunction = QTable()
QLearning(mdp, EpsilonGreedy(), qfunction).execute(episodes=200)
policy = QPolicy(qfunction)
mdp.visualise_q_function(qfunction)
mdp.visualise_policy(policy)
q_learning_rewards = mdp.get_rewards()

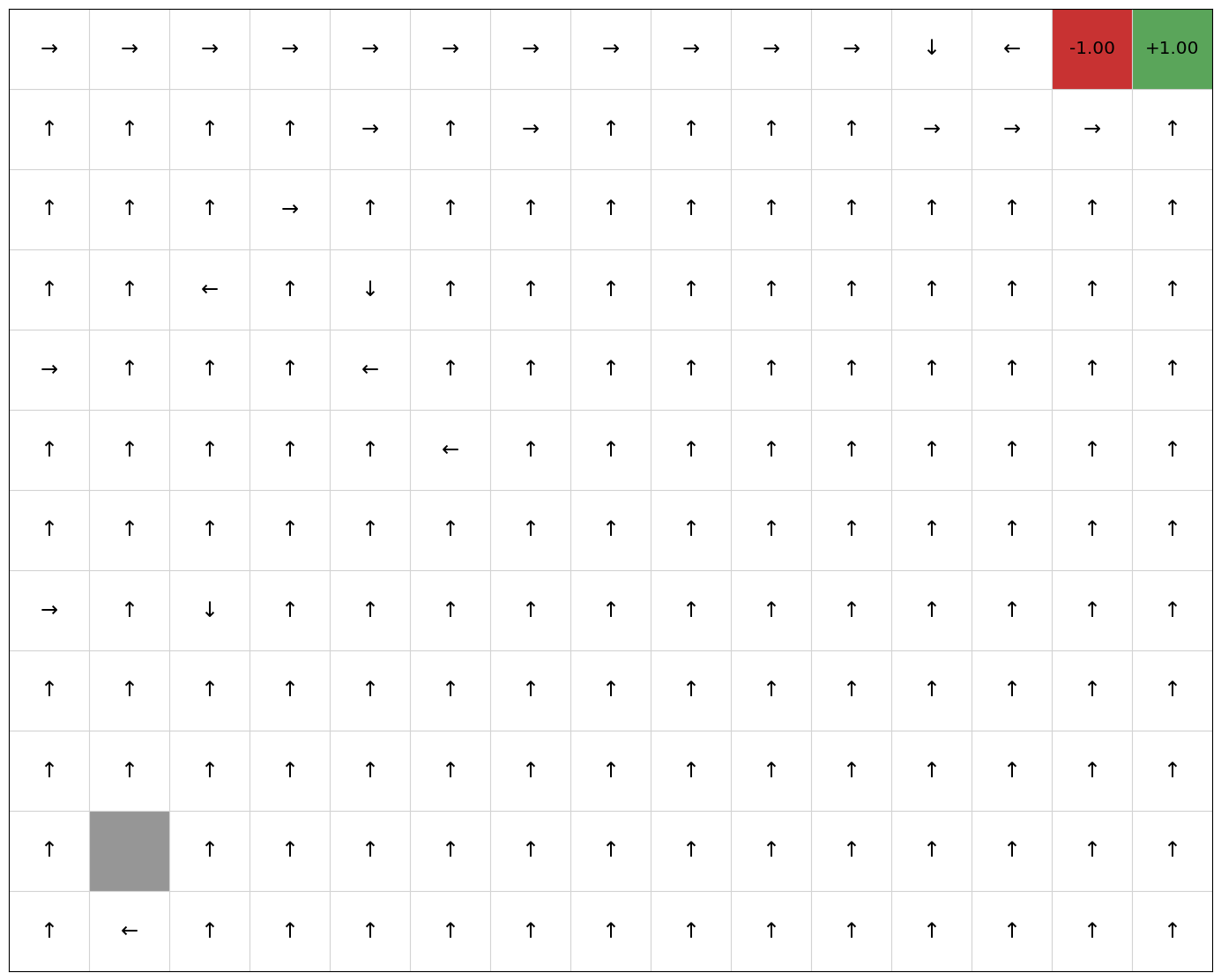
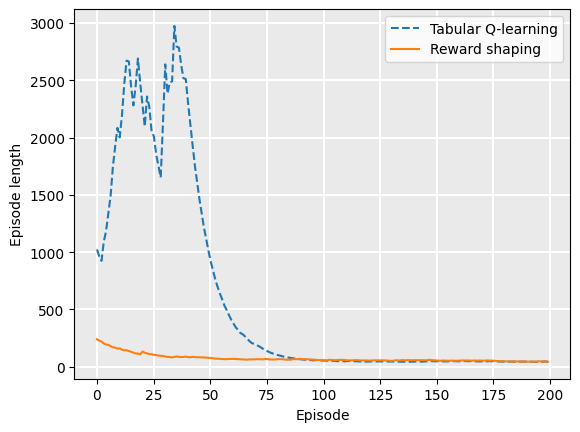
If we plot the average episode length during training, we see that reward shaping reduces the length of the early episodes because it has knowledge nudging it towards the goal:
from tests.plot import Plot
Plot.plot_episode_length(
["Tabular Q-learning", "Reward shaping"],
[q_learning_rewards, reward_shaped_rewards],
)
Q-value initialisation
An approach related to reward shaping is Q-value initialisation. Recall that TD learning methods can start
at any arbitrary Q-function. The closer our Q-values is to the optimal Q-values, the quicker it will converge.
Imagine if we happened to initialise our Q-values to the optimal Q-value. It would converge in one step!
Q-value initialisation is similar to reward shaping: we use heuristics to assign higher values to ‘better’ states. If we just define [latex]\Phi(s) = V_0(s)[/latex], then they are equivalent. In fact, if our potential function is static (the definition does not change during learning), then Q-value initialisation and reward shaping are equivalent[1].
Example – Q-value Initialisation in GridWorld
Using the idea of Manhattan distance for a potential function, we can define an initial Q-function as follows for state (1,2) using our potential function:
[latex]\begin{split} \begin{array}{llllr} Q((1,2), Up) & = & 0.9(1 - \frac{2}{5}) - (1 - \frac{2}{5}) & = & -0.06\\ Q((1,2), Down) & = & 0.9(1 - \frac{2}{5}) - (1 - \frac{2}{5}) & = & -0.06\\ Q((1,2), Right) & = & 0.9(1 - \frac{1}{5}) - (1 - \frac{2}{5}) & = & 0.12\\ Q((1,2), Left) & = & 0.9(1 - \frac{3}{5}) - (1 - \frac{2}{5}) & = & -0.24 \end{array} \end{split}[/latex]
Once we start learning over episodes, we will select those actions with a higher heuristic value, and also we are already closer to the optimal Q-function, so will will converge faster. As with reward shaping though, this entirely depends on having a good potential function! A poor potential function will give an inaccurate initial Q-values, which may take longer to converge.
Takeaways
- A weakness of model-free methods is that they spend a lot of time exploring at the start of the learning. It is not until they find some rewards that the learning begins. This is particularly problematic when rewards are sparse.
- Reward shaping takes in some domain knowledge that “nudges” the learning algorithm towards more positive actions.
- Q-value initialisation is a “guess” of the initial Q-values to guide early exploration
- Reward sharping and Q-value initialisation are equivalent if our potential function is static.
- Potential-based reward shaping guarantees that the policy will converge to the same policy without reward shaping.
